Christopher “Tony” Bucchere
Software Developer
·
Writer
·
Home Chef
·
Lindyhopper
·
Dad
Categories
Subscribe on Substack
Random Post
Explore
2026
Fixed the door handle on a 2013 Model S
August 2, 2026 ·
Personal
Fun little project, first time disassembling an electric car. Didn't fry myself, that's good. / The OG Tesla retractable door handles are arguably…
Sausage & Peppers
July 31, 2026 ·
Cucina Mia
Italian comfort food. I don't know why the potatoes aren't mentioned in the name, because arguably they're the best part.
Spaghetti Carbonara
July 27, 2026 ·
Cucina Mia
Basically breakfast for dinner, with some peas.
Classic Wedge
July 27, 2026 ·
Cucina Mia
Iceberg lettuce, red onion, cherry tomato, blue cheese dressing, bacon crumbles. Colored outside the lines a little by adding pickled jalapeños.
Neapolitan Pizza and a Spinach Calzone
July 26, 2026 ·
Cucina Mia
First Harvest
July 18, 2026 ·
Cucina Mia
It’s a short growing season here in the high desert, but this little mini harvest is foreshadowing what’s to come (I hope). Good time to be growing…
Curried Chicken Salad Melt
July 11, 2026 ·
Cucina Mia
I don’t mess around with lunch. Curried chicken salad melt, extra sharp cheddar, avocado mayo, sriracha on a toasted brioche roll with a side of…
2025
Maddy and I planted a Peach Tree
July 5, 2025 ·
Personal
·
Parenting
·
Cucina Mia
The variety is “Hale Haven,” and according our still-benevolent robot overlords: Developed at Michigan State University's South Haven Experimental…
2024
Hawaiian Sweet Rolls
July 21, 2024 ·
Cucina Mia
How could these not be amazing when there’s pineapple juice in the dough?
2022
Career Move
January 30, 2022 ·
Fiction About True Stuff
·
Substack
·
Parenting
The bell rings ding dong / But the wicked witch ain't dead / She's out of my heart / But still in my head / Calling me crazy and dangerous / Saying I…
Pain
January 3, 2022 ·
Fiction About True Stuff
·
Substack
·
Parenting
Does the onion start crying / When you peel off his skin? / Do the screams of the bell peppers ring / Echoing in the oven as they're cooking? / Does…
2021
A Hello to Arms
December 25, 2021 ·
Fiction About True Stuff
·
Substack
·
Parenting
I guess it’s just your nature / To treat her not as her own creature / But more like an arm / Cover it up to keep it warm / When it’s cold outside /…
The Three Rules
December 14, 2021 ·
Fiction About True Stuff
·
Substack
·
Parenting
·
essay
After two decades / We’re a sorry, suffering lot / Your temper and your rage— / A true despot! / But we found a way to keep the peace / (Still…
Imaginary Monster
December 11, 2021 ·
Fiction About True Stuff
·
Substack
·
Parenting
You must be scared of it: / The monster you imagined in me / I’m way less scary than these guys ® Disney Corporation / Does it make you crazy? /…
Busted Lap
December 8, 2021 ·
Parenting
·
Fiction About True Stuff
·
Substack
December 5th, 2021 / The world is wrong today / An Uber driver speaks of his wealth / When he's just one small step / From the corner bums and their…
Once Upon a Hot Tub
November 28, 2021 ·
Fiction About True Stuff
·
Substack
·
Parenting
·
essay
·
travel
Do you know how whored I feel right now? / Frankly I didn’t know the word “whored" could be used in that way / So it threw me off— / Not that I had a…
Lamentation #45
November 4, 2021 ·
Fiction About True Stuff
·
Substack
·
Parenting
The Macchiato Conversation
October 8, 2021 ·
Cucina Mia
·
Fiction About True Stuff
·
Substack
·
Parenting
·
essay
By now haven’t we all had / The macchiato conversation? / You know when you try to order one / At an authentic coffee shop— / Not a Peet’s or a…
I Don't Like My Cat
October 6, 2021 ·
Fiction About True Stuff
·
Substack
·
Parenting
·
essay
I don’t like my cat / He sits in my favorite chair / And watches me / He yells at me to get me to play with him / But then he won’t play with me /…
Rescued from Summer Camp
October 3, 2021 ·
Fiction About True Stuff
·
Substack
·
Parenting
·
essay
I blink— / Or at least that’s what I thought I did / But when I open my eyes / I realize my car has traveled— / Into a different lane / My heart…
Kalamata's Best for Bread
September 18, 2021 ·
Cucina Mia
After trying every olive I could find, I’ve figured out what everyone in bread making already knows: the Kalamata is top dog. Funny I don’t really…
To Return a Wetsuit
September 17, 2021 ·
Fiction About True Stuff
·
Substack
·
Parenting
·
essay
I stand a bit hunched over behind my car— / A secondhand 2013 navy blue Tesla Model S / In an empty parking lot / Between two nondescript warehouses…
How to Fall in Love with a Friend
September 14, 2021 ·
Highlights
·
Personal
·
Fiction About True Stuff
·
Substack
·
essay
·
Lindyhop
Can I touch your hair? / She asks me / A strange question indeed / We’re standing next to one another / At Ocean Beach / Atop the O'Shaughnessy…
Forgetting Something?
September 3, 2021 ·
Cucina Mia
·
bagels
·
Fiction About True Stuff
·
Substack
·
cycling
·
travel
Shit! / What, you ok? / Now I’m feeling bad for startling the Lyft driver / I mean we’re halfway to SFO already / Heading down 101 through the…
El Paseo, 2019-2020
September 2, 2021 ·
Activism & Politics
·
Fiction About True Stuff
·
Substack
·
Parenting
·
essay
Mill Valley looks like the kind of town / You’d expect to see in a model railroad set / Minus the trains— / Tracks torn up / After a massive fire /…
Brooklyn, c. 1985
August 30, 2021 ·
Cucina Mia
·
Highlights
·
Personal
·
essay
They don’t tell you in San Francisco / That East Coast nights don’t cool down in the summer / Not in Augusta / But not in Brooklyn either / I…
Tonight’s craft cocktail
August 25, 2021 ·
Cucina Mia
·
drink at home
A Rosemary Fashioned: Bulleit Bourbon, house-extracted rosemary syrup, Pechaud's Bitters, rocks, sprig of rosemary garnish
Saturday Dinner
August 22, 2021 ·
Cucina Mia
·
fusion
Clockwise from left: au gratin with russets, leeks, jalapeños, cumin, and crumbled paneer; green beans with olive oil, kosher salt, and sautéed…
A Marine's Choice
August 18, 2021 ·
Activism & Politics
·
essay
·
travel
Anyone who traveled with Mitch Ludwig / Knew about the shrapnel in his ass / It was from Vietnam / A Marine / Two tours / And a Purple Heart / A man…
Cucina Mia has a YouTube Channel
August 12, 2021 ·
Cucina Mia
To make it easier to find all my cooking tutorials, I've dropped them into a YouTube channel. / Impossibolognese is my next meatless challenge,…
Caponata inspired by #delarosa, Mazanella olive loaf inspired by #tartine
August 9, 2021 ·
Cucina Mia
·
Facebook
·
#delarosa
·
#tartine
Giant artichokes, pressure cooked, halved, grilled, then stuffed with cream...
August 8, 2021 ·
Facebook
·
Cucina Mia
·
#misenmade
cheese, prosciutto, onions, sweet red peppers and panko, then finished in the broiler #cucinamia #misenmade
The Weight
August 7, 2021 ·
pandemic
When you feel the weight of the world / Upon your shoulders / It is an illusion / For you are the world / And the world is you / And it is heavy /…
See, the world IS becoming a better place
August 6, 2021 ·
Facebook
A Stranger in San Pancho
August 5, 2021 ·
travel
·
Fiction About True Stuff
·
Substack
·
Parenting
·
Lindyhop
It’s 3:30am in San Pancho / Our legs are numb from dancing / And the mezcal has got us wondering / If we’re still drunk or starting to get hungover /…
Tartine process works at 5000’ without any modifications!
August 2, 2021 ·
Cucina Mia
·
Facebook
Washing Pennies
August 1, 2021 ·
Featured Posts
Violent thunderstorms would often strike Freeport, GBI. I was four years old, but I can feel them like it was yesterday. Several times a day, mothers…
The best part of Dolsot Bibimbap!
July 30, 2021 ·
Facebook
Curious George
June 28, 2021 ·
Activism & Politics
·
cycling
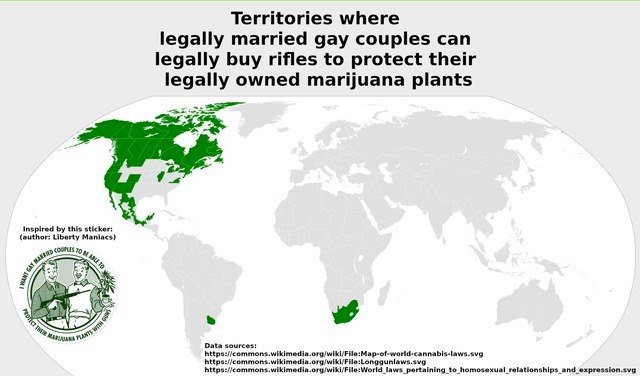
Shortly after George Gascón turned my bicycle accident into the Crime of the Century™, he was run out of San Francisco by BLM activists and Colin…
Making my own cola syrup with alcohol, sugar, and pressure extraction
June 23, 2021 ·
Cucina Mia
·
Facebook
Once there were parking lots /
June 22, 2021 ·
Facebook
Now it's a peaceful oasis
¡Aye caramba!
June 21, 2021 ·
Facebook
Lizzy's recording again
June 15, 2021 ·
music
So happy to help support my favorite modern big band out of Los Angeles: Lizzy & The Triggermen.
Celebrating my 2nd 45th birthday with my two favorite women 🥳
June 12, 2021 ·
Facebook
This one
May 25, 2021 ·
Facebook
Twelve calzones and a car
May 24, 2021 ·
Cucina Mia
·
Facebook
As promised, Rigatoni & Impossible Balls!
May 21, 2021 ·
Facebook
·
#impossiblenonna
·
Cucina Mia
·
#impossiblefoods
·
#impossibleburger
·
#misenmade
·
#tabasco
·
#instantpot
·
#cuisinartas
·
#cuisinart
#impossiblenonna #cucinamia #impossiblefoods #impossibleburger #misenmade #tabasco #instantpot #cuisinart
Okay, so I guess I'm not doing anything today
May 20, 2021 ·
Facebook
The Impossible Nonna
May 18, 2021 ·
Cucina Mia
·
impossible nonna
I've been troubled by the horrors of industrial beef production for at least a decade, but I've never done anything about it—until NOW. / "The…
Boy, this is complicated
May 15, 2021 ·
Activism & Politics
San Francisco once had a corrupt, law-enforcement-simping, pro-crime-porn DA (George Gascón) who BLM ran out of town over the Mario Woods…
← Newer
Page 1 of 14
Older →